본 논문은 2018 Nips oral presentation으로 발표된 구글 브레인 논문입니다. 해당 논문은 뇌인지과학 개념을 적용한 강화학습 모델을 제안하였습니다.
Introduction
System dynamics의 창시자인 Jay Wright Forrester는 mental model에 관하여 다음과 같은 말을 했습니다.
“The image of the world around us, which we carry in our head, is just a model. Nobody in his head imagines all the world, government or country. He has only selected concepts, and relationships between them, and uses those to represent the real system.”
위의 말을 정리하자면, 사람들이 세상을 보고 이해할 때, 세상 전체를 모두 받아들이는 게 아니라 콘셉트, 관계 등을 통해 세상을 표현한다는 것입니다.
즉 많은 양의 정보가 들어오면 뇌(model)에서는 이러한 정보를 전부 받아들여 저장하는 것이 아니라, 정보들의 추상적인 정보를 가지고 세상을 인지한다는 말입니다.
또한 이렇게 들어온 정보들은 세상을 바라보는 시점 뿐만 아니라 어떤 ‘action’을 행할지 예측하는 모델 개념으로도 이해할 수 있습니다. 예로 위험한 상황에 처했을 때 사람들은 의식적으로 다음 행동을 계획하지 않고 즉각적으로 반응합니다.

야구를 예로 들었을 때, 야구 선수들은 야구 방망이를 어느 방향으로 휘두를지 극도로 짧은 순간 내에 결정합니다. 이는 시각 정보가 뇌까지 들어오는 속도보다 훨씬 짧습니다. 이는 야구 선수들 같은 경우는 이런 식으로 예측하는 ‘model’과 그에 반응하는 근육들(controller)들이 잘 훈련되었다고 할 수 있습니다.
RNN은 시간적 순서를 통해 미래를 예측하는 모델입니다. 즉 사건에 대한 시간적 특성을 표현할 수 있는 모델이란 뜻입니다. 하지만 이렇게 파라미터가 많은 모델을 바로 agent에 사용할 경우 credit assignment problem(어떤 경우에 얼마나 보상을 해야 하는지 결정하는 행위)이 발생할 수 있습니다. 따라서 일반적인 강화학습에서는 파라미터의 수가 적은 model-free RL을 사용합니다.
본 논문에서는 RNN을 model로 사용하는 model-based RL을 제안하였습니다. 모델의 효과적인 학습을 위해 크게 두개의 모델로 나누었으며, 각각 large model과 smaller controler model입니다. Large model은 다음 장면의 추상화된 정보들을 맞추는 역할을 합니다. Controller model의 경우에는 credit assignment problem을 해결하는 역할을 합니다.
Agent Model

Agent 모델은 크게 3가지 구조로 구성되어 있습니다.
- Vision Model(V) : VAE
- Memory Model(M) : MDN-RNN
- Controller Model(C) : Simple single layer linear model
Vision Model(V)

먼저 environment를 encode시키는 VAE입니다. 해당 구조는 사람의 눈에 해당하는 역할을 합니다. 눈으로 보는 환경, 즉 영상으로 표현되기에 입력으로는 영상의 프레임으로 이루어져 있습니다. 이를 controller에 바로 연결하는 것은 힘들어 VAE를 거쳐 영상의 특징이 압축된 latent vector z를 사용합니다.
Memory Model(M)
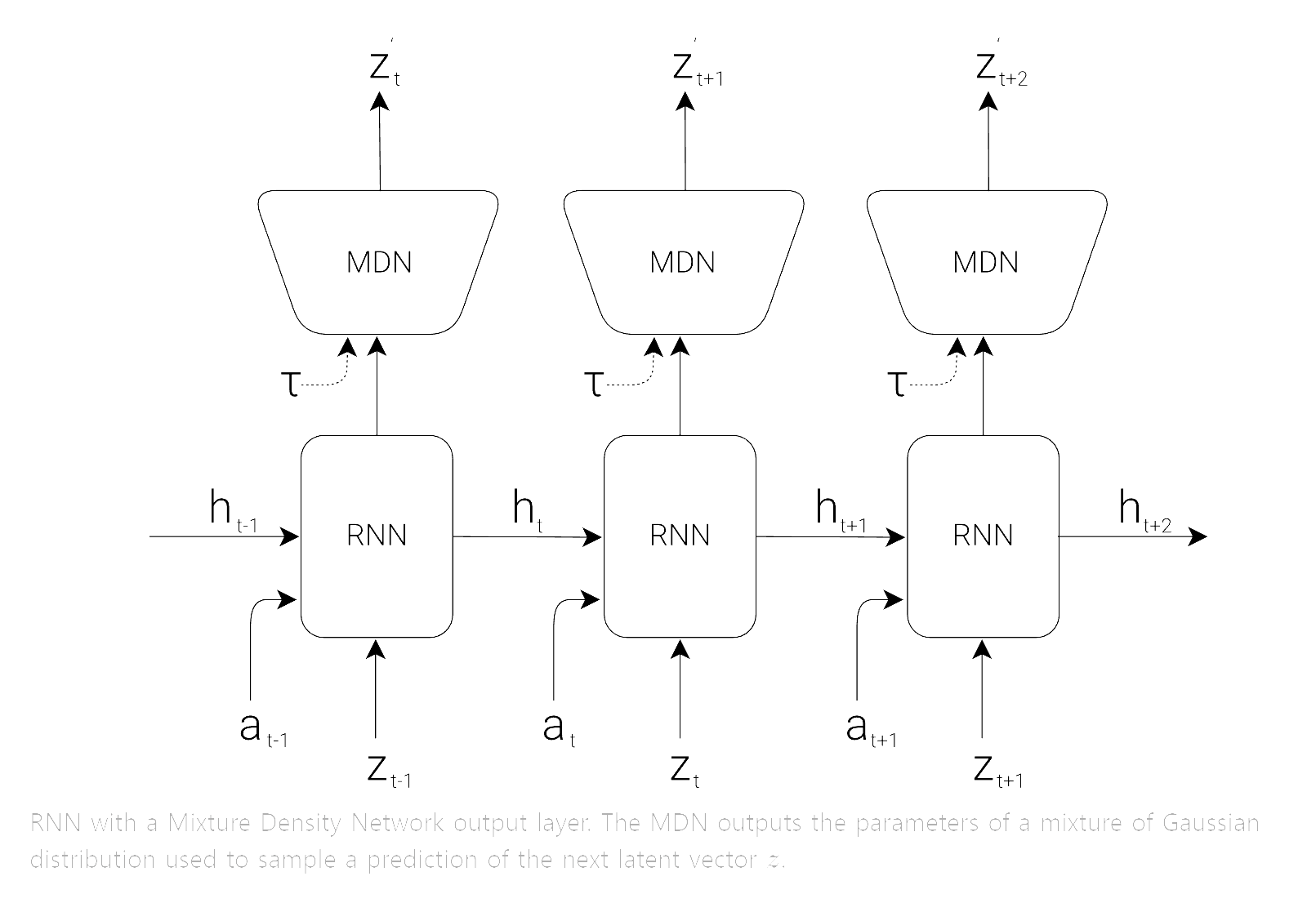
위의 Vision Model을 통해 영상의 특징이 압축된 latent vector z를 얻는다면, Memory Model의 역할은 시간적 순서에 맞게 다음으로는 어떤 상황이 발생하는지 예측하는것입니다. 이렇게 순차적 데이터를 사용하여 미래를 예측하는 모델로는 RNN계열의 모델이 가장 효율적이기에 본 논문에서는 RNN을 사용하였습니다. 추가적으로 논문에서는 RNN에 MDN개념을 적용합니다. 이를 통해 RNN의 output은 단순히 하나의 값이 아니라 probability density function P(z)으로 나오게 됩니다.
Controller Model(C)
Controller는 environment가 지속적으로 변하는 상황에서 누적보상의 기댓값을 최대화하기 위한 action을 정합니다. 논문에서는 V와 M과 따로 학습을 시키기 위하여 일부러 최대한 파라미터 수가 적으면서도 간단한 모델을 만들었습니다. 수식으로 나타내면 아래와 같습니다.
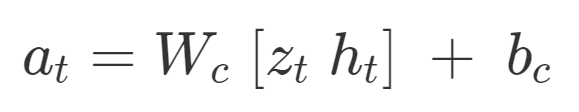
- at : action vector
- Wc : weight
- bc : bias
위의 수식을 보면 Zt, ht에 대한 1차 함수라는 것을 확인할 수 있습니다.
Putting Everything Together

위의 전체적인 구조를 본다면 관측된 데이터(observation)가 들어오면 해당 프레임의 특징을 압축한 latent vector z가 VAE를 통해 생성됩니다. z를 M 모델에 입력으로 넣어 hidden state ht를 생성합니다. 그리고 latent vector z와 hidden state ht를 C 모델에 넣고 action vector at를 계산합니다. 마지막으로는 at, z, ht를 M 모델에 넣어 다음 프레임에 사용될 hidden state ht+1을 생성합니다.
Conclusion
이번 포스트에서는 World Models 논문에서 소개된 모델의 전체적인 구조에 대해 소개했습니다. 더 자세한 내용은 논문 저자의 블로그에서 확인할 수 있습니다. 다음 포스트에서는 실험결과에 대해 소개하도록 하겠습니다.
'황민규 > 논문 스터디' 카테고리의 다른 글
| World Models(Experiment) (0) | 2023.02.14 |
|---|
