1편에 이어서 2편에서는 Word Embedding 알고리즘이 발전해온 순서에 맞춰서 소개하도록 하겠습니다.
- Word2Vec
- Glove
- FastText
1. Word2Vec
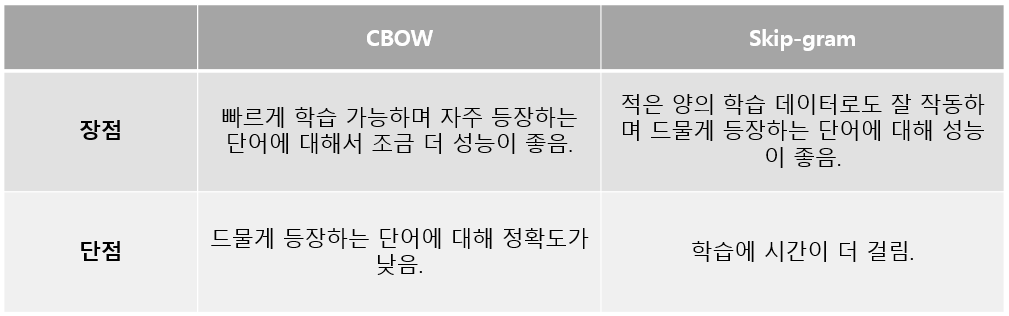
말 그대로 단어를 벡터로 바꾸는 알고리즘으로 1편에서 다룬 BOW보다 발전된 알고리즘입니다. 크게 2가지 방식을 통해 단어를 벡터로 변환합니다.
1.1 CBOW(Continuous Bag-of-Word)
문장의 주변 단어를 통해 중심 단어를 예측하는 임베딩 알고리즘입니다. 미닫이 창문을 밀어서 이동하는 것과 비슷한 window라는 개념이 사용됩니다.
예를 들어, window size = 2라고 하면 아래와 같은 문장에서 붉은 글씨가 중심 단어이고 밑줄 그은 단어들은 중심 단어로부터 widow size 안쪽에 위치한 주변 단어들입니다.

이런 식으로 주변 단어들을 이용해서 중심에 어떤 단어가 들어올지 예측을 하는 방식으로 중심 단어와 주변 단어들을 원 핫 벡터로 나타내 데이터 셋을 만듭니다. 문장의 처음부터 끝까지 모든 단어를 중심으로 데이터 셋을 만들며, 처음이나 끝의 단어처럼 한쪽 window가 없는 경우 없는 대로 만듭니다.

이렇게 만들어진 데이터 셋을 이용해서 중심 단어를 예측합니다. 아래는 CBOW 신경망 모델을 간단하게 도식화한 것입니다.

a. Input Layer에는 각각 window size에 맞는 수의 '주변 단어 원 핫 벡터(vector size = V)'가 input으로 들어갑니다.
b. 이후 PL(Projection Layer)을 통과합니다. 이 PL은 Deep Neural Network와는 달리 hidden layer가 1개인 shallow network입니다. 그리고 활성화 함수가 존재하지 않는 º Lookup tabel 연산을 진행하므로 Projection Layer라고 불립니다.
- Lookup table 연산이란?
아래의 그림처럼 특정 Weight matrix (W)와 원 핫 벡터를 연산한 결과가 W 벡터의 원 핫 벡터의 1의 위치(4번째)와 동일한 것이 표를 그대로 읽어오는 것과 같다고 하여 Lookup table 연산이라고 합니다. x의 1의 위치(4번째)에 해당하는 W의 행벡터(4번째)가 연산의 결과입니다.

c. PL을 통과한 벡터는 각각 [V x D] 크기의 W(weight matrix)와 연산을 통해 size D인 벡터가 되며 이를 모두 weight average 하여 하나의 D차원 벡터 D로 만듭니다.
d. 이렇게 만들어진 D를 W와 Transpose 형태의 W ' matirx 연산 후 softmax를 거쳐 다시 input vector V와 동일한 크기의 확률 벡터(prediction)를 만듭니다. 이때, W '은 W와 전치(transpose) 행렬 관계가 아닌 별개의 행렬이며 이 두 개의 W와 W '을 학습시킵니다.
e. 최종적으로 만들어진 predition 벡터와 정답 벡터의 차이(Cross Entropy Loss)를 줄이는 방향으로 신경망이 학습됩니다.
CEL(Cross Entropy Loss)

위와 같은 과정으로 만들어진 신경망이 CBOW입니다.
1.2 Countinuous Skip-Gram
Skip-Gram은 CBOW와 반대로 중심 단어를 통해서 주변 단어를 예측하는 알고리즘입니다.

중심 단어 1개를 통해서 주변 단어를 예측하므로 PL 단계에서 평균을 내는 과정은 없습니다. 나머지 과정은 대부분 동일합니다.
GloVe와 FastText는 이어지는 글에서 소개하도록 하겠습니다.
'오성연 > Natural Language Processing' 카테고리의 다른 글
| [NLP - 기초 #4] Word Embedding - FastText (0) | 2023.01.05 |
|---|---|
| [NLP - 기초 #3] Word Embedding (0) | 2022.12.22 |
| [NLP - 기초 #1] Word Embedding (2) | 2022.12.01 |


