Word Embedding
NLP(Natural Language Processing)는 자연어(Natural Language) 즉 우리가 일상적으로 말하고 글로 적는 언어를 컴퓨터가 이해할 수 있는 언어(숫자)로 바꿔서 인공지능에 활용하는 것이다. 인공지능이 자연어를 이용하기 위해서 텍스트를 숫자 형태(벡터)로 바꾸는 방법을 찾아야 하며 그 방법이 Word Embedding입니다.
이러한 Word Embedding은 자연어(text)를 숫자 형태로 바꾸기 위한 시도로부터 시작했고 text를 숫자 형태로 바꾸기 위한 방법은 아래의 순서대로 발전해왔습니다.
- One-Hot Encoding
- BOW(Bag-of-Words)
- Word Embedding
0. Vocabulary
NLP에서 Vocabulary(Vocab)란 내가 처리하고자 하는 text 전체의 집합을 의미합니다. 이것은 특정 소설의 본문일 수도 있고, 여러 개의 뉴스 기사일 수도 있습니다. 이때, text는 토큰(token)의 형태로 만들어집니다.
토큰을 만드는 방법을 토크나이징(tokenizing)이라고 하며 문장을 띄어쓰기 대로 끊어서 토큰으로 만드는 것이 쉽게 생각할 수 있는 토크나이징 방법입니다.
예를 들어, "I am a student"라는 문장을 띄어쓰기 대로 끊어서 토큰으로 만들면 [ I, am, a, student ] 과 같이 4개의 토큰으로 나타낼 수 있게 되는 거죠.
토크나이징에는 띄어쓰기로 끊어 쓰는 것뿐만 아니라 다양한 방식이 존재하는데 이는 따로 다루도록 하겠습니다.
1. One-Hot Encoding(OHE)
원핫 인코딩(One-Hot Encoding) 이란 단어를 vocab의 순서에 맞게 라벨링한 벡터로 만드는 방법입니다. 1이면 단어가 있는 것이고 0이면 없는 것입니다. Vocab의 크기를 n이라고 가정할 때 각 단어는 n 차원의 벡터로 나타낼 수 있고 문장은 (n x n) 형태의 matrix로 나타낼 수 있습니다.

예를 들어 위의 왼쪽 사진처럼 able부터 zombie까지 총 9999개의 단어가 모인 vocab이 있다고 가정하겠습니다.
island라는 단어는 9999개의 vocab 중에 5282번째에 해당하며 이를 벡터로 나타내면 9999차원의 벡터 중에 5282번째만 1인 벡터 (0, 0, ..., 0, 1, 0, ... , 0) 로 나타낼 수 있습니다.
다른 예시인 오른쪽 사진처럼 Document1(Doc1)과 Document2(Doc2)의 2개의 문장이 있을 때, 빨간색 네모로 표시한 박스는 7개(size = 7)의 단어로 구성된 vocab입니다. 위의 vocab에 맞춰서 아래와 같이 Doc1, Doc2 문장을 7x7 matrix로 나타낼 수 있습니다.

2. BOW(Bag-of-Words)
BOW는 문서 또는 텍스트 청크(일반적으로 문장)에서 모든 고유한 단어의 발생 및 동시 발생 수를 계산하는 방식입니다. 그런 다음 각 텍스트 청크(문장)는 행렬의 행으로 표시되며, 여기서 열은 단어를 의미합니다.

예를 들어 앞서 사용한 예시와 같이 Doc1, 2가 있을때 이것을 OHE 방식과 달리 아래처럼 나타낼 수 있습니다.

하나의 행으로 문장에 포함된 단어를 표현하는 방식이고 여러 번 등장하는 단어는 2, 3 등 단어가 등장하는 횟수를 표시하여 벡터로 나타냅니다. 이는 개별 단어의 수가 적고 감정 분석에서와 같이 단어의 순서가 핵심적인 역할을 하지 않는 경우에 특히 유용합니다.
Limitation of OHE and BOW
OHE와 BOW 방식의 접근을 통해 생성된 word vector를 인공지능 모델의 input 사용할 때 문제가 발생합니다. Vocab 크기가 크면 벡터의 크기가 커지는 반면 문장에 포함되는 단어의 수는 제한적이므로 굉장히 sparse 한 벡터가 만들어집니다.

예를 들어 위의 사진처럼 size = 1,000,000 즉, 단어의 종류가 백만 개인 vocab에서 "I am a student"라는 문장을 BOW를 이용해 벡터로 만든다고 가정하면, 엄청나게 많은 0과 4개의 1로 구성된 벡터가 생성된 것을 알 수 있습니다. 이런 sparse 한 벡터는 불필요한 정보(0)가 너무 많아져서 효율을 떨어뜨리고 모델을 학습하는데 도움이 되지 않는 문제를 야기합니다.
하지만 OHE나 BOW 방식의 더 큰 문제점은 두 단어 간의 유사성을 알 수 없다는 것입니다.
예를 들어 "Cat eats meat"라는 문장을 한 글자만 바꿔서 "Car eats meat"이라는 문장으로 바꾸면 말이 되지 않습니다. 하지만 Cat을 Tiger로 대체하면 말이 됩니다.

Cat은 Car와 한 글자 차이가 나지만 의미적으로는 아예 다른 성질을 가집니다. 반면 Cat과 Tiger는 글자는 달라도 둘 다 고양이과에 속하며 비슷한 성질(동물, 4족 보행, 육식성 등)을 공유해 의미적으로 비슷한 성질을 가집니다. 사람은 이 차이를 알고 있기 때문에 문장의 단어를 비슷한 성질의 단어로 바꿨을 때 말이 된다는 것을 알 수 있지만 컴퓨터는 이 차이를 알지 못하죠.

그래서 컴퓨터에게 특정 단어를 단순히 벡터로 바꾸는 것을 넘어 의미적인 유사성을 알려줘야 했습니다.
Overcome limitation = Word Embedding
이러한 한계를 극복하기 위한 방법이 바로 Word Embedding입니다. 워드 임베딩은 n차원의 다양한 축을 가진 벡터로 단어를 표현합니다. 예를 들어 아래 그래프처럼 귀여움(cuteness)과 무서움(scariness) 2개의 축으로 다양한 단어를 표현해 보겠습니다.

quokka를 벡터로 나타내면 무서움 0, 귀여움 1 (0, 1)로 나타낼 수 있습니다. 반면 zombie는 무서움 1, 귀여움 0 (1, 0)으로 나타낼 수 있습니다. 이런 방법으로 tiger와 rat 역시 벡터로 나타낼 수 있습니다. 또한 각 단어 벡터들을 아래의 예시처럼 대수적인 계산 방식으로 나타내는 것도 가능합니다.
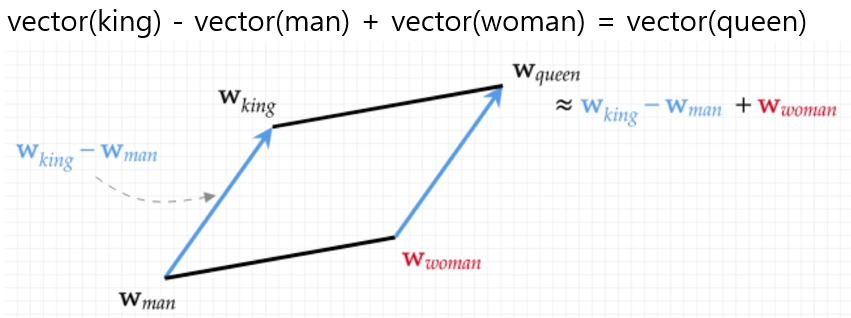
이러한 워드 임베딩 방식을 다른 언어로 번역을 할 때 유용하게 사용할 수 있습니다. Source 언어(예를 들어, English)의 단어 벡터를 번역할 언어(Spanish)의 벡터 공간에서 가장 가까운 벡터를 검색하여 번역을 합니다.

위의 그림처럼 각 언어에서 같은 의미를 가지는 단어가 비슷한 위치의 Embedding Space(임베딩 벡터로 이뤄진 공간)에 존재하기 때문입니다. 영어에서 4를 뜻하는 four의 위치와 스페인어에서 4를 뜻하는 cuatro는 비슷한 임베딩 공간에 존재하는 것을 볼 수 있으며 다른 단어들 역시 비슷한 것을 알 수 있습니다.
어떻게 언어가 다른데 비슷한 의미의 단어가 각각 비슷한 임베딩 공간에 존재할 수 있을까요? 그 이유는 한 언어의 단어 벡터가 다른 언어와 유사한 맥락에서 사용되기 때문입니다. 즉, 영어의 four가 영어에서 사용되는 맥락이 스페인어의 cuatro가 사용되는 맥락과 비슷하기 때문에 비슷한 임베딩 공간에 존재한다는 뜻입니다.
이러한 word embedding에는 크게 3가지 방식이 있는데 이는 다음 글에서 다루도록 하겠습니다.
'오성연 > Natural Language Processing' 카테고리의 다른 글
| [NLP - 기초 #4] Word Embedding - FastText (0) | 2023.01.05 |
|---|---|
| [NLP - 기초 #3] Word Embedding (0) | 2022.12.22 |
| [NLP - 기초 #2] Word Embedding (0) | 2022.12.15 |


